
ThreadLocal是JDK java.lang包下比较常用的工具类,实现了线程上下文的功能,最常见的应用应该就是用ThreadLocal来存放登录过后的用户上下文等关键信息。
线程上下文还可以优雅的解决很多看起来比较复杂的问题,比如:spring-mybatis框架的整合问题:
在基于spring生态开发的时候我们一般都是将事务委托给spring管理,通过transactional注解去配置开启事务,以及事务的隔离级别等信息。我们操作数据库也不是直接通过jdbc,而是通过mybatis框架来访问数据库。spring和mybatis是两个完全独立的框架,但是我们在使用的时候,似乎由spring开启的数据库connection直接就可以被mybatis获取使用,我们基本啥也不用干,引入一个mybatis-spring-boot-stater的jar包就可以了。
这个优雅的设计实现的关键点就是ThreadLocal,大体原理是stater jar包会最终帮我们引入一个MybatisAutoConfiguration并通过SPI注入到我们服务的bean容器里,在MybatisAutoConfiguration中配置好了mybatis需要的SqlSessionFactory,并注入了spring自己的SpringManagedTransactionFactory(实现了TransactionFactory,事务工厂是mybatis提供的扩展机制,可以把事务管理委托出去)。
整体的执行流程就是transactional注解的方法最终会被AOP代理,代理类会在前置的通知中从dataSource获取一个connection,并最终放到一个ThreadLocal中(其实ThreadLocal里放的是一个map,key是dataSource,value是connectionHolder等同于connection),后续mybatis执行sql的时会先通过TransactionFactory获取connection,因为此时注入的TransactionFactory是SpringManagedTransactionFactory,所以会从ThreadLocal取出对应dataSource的connection。
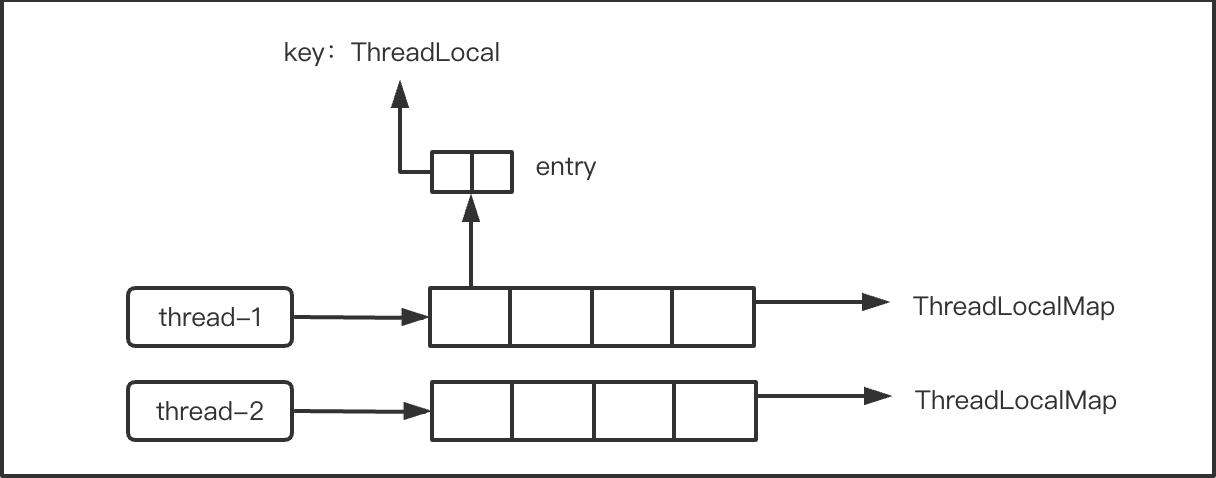
ThreadLocal简单原理介绍:
ThreadLocalMap就是一张采用线性探测法解决冲突的哈希表,每个线程都会生成一份,每个ThreadLocal对象里都有一个threadLocalHashCode用来计算hash key。
对比一下HashMap,ThreadLocalMap选择的冲突算法是线性探测而不是拉链法可能基于以下考虑:
1、内存考虑,因为使用场景不同,ThreadLocalMap的数据量一般会远小于HashMap,在小数据量情况下拉链法的会多出很多指针的空间消耗
2、效率,在1的基础上,小数量情况下省下来的空间可以用来生成一个装填因子较小的哈希表,减少冲突,提高平均查找速度
问题
A 在基于线程池的任务场景中,存在上下文传递问题,尤其是在基于Tomcat的web编程模型中,由于Tomcat本身是使用线程池来处理服务器与客户端间的请求-相应交互,每个web应用都不得不手动处理线程上下文正确传递问题。
B 效率问题,如果应用中的ThreadLocal过多,导致哈希表膨胀以后,查找速度会下降
针对问题A,常见的解决方式比较统一,直接贴一下我们系统里的代码
这种方案存在两个问题:
1、如果后续有新增的ThreadLocal需要正确传递,则需要修改代码在wrap逻辑中加上新ThreadLocal,一旦遗漏就会出bug
2、在一些场景任务可能会由提交线程自己执行,比如:
当线程池满了且线程池的
RejectedExecutionHandler使用的是CallerRunsPolicy时,提交到线程池的任务会在提交线程中直接执行,此时最后的清除逻辑会导致提交线程的上下文丢失类似的,使用
ForkJoinPool(包含并行执行Stream与CompletableFuture,底层使用ForkJoinPool)的场景,展开的ForkJoinTask会在任务提交线程中直接执行。最后的清除同样会导致提交线程的上下文丢失
解决方案:
问题1:如果ThreadLocal类支持一个API,可以获取应用里现在一共有多少ThreadLocal对象,那么迎刃而解了,可惜不支持。强行做的话,可以通过反射获取thread对象里的inheritableThreadLocals(就是一个ThreadLocalMap)属性,然后遍历哈希表取出所有的entry就可以得到所有threadlocal键值对。另一种思路就是对jdk的ThreadLocal再做一层封装,增补上述的功能。
问题2:可以通过完善wrap的逻辑解决:在线程初始运行时先获取当前线程的上下文进行暂存,然后再用提交线程的上下文替换本线程的上下文,线程运行结束前不进行清除,而是改为使用暂存数据还原本线程的上下文。
transmittable-thread-local
轮子已经有现成的了,实现原理就是从上面两个方向着手的,并且给这个流程起了个名字 CRR(capture/replay/restore) 模式。
使用方式有三种:
1 ### 修饰 Runnable 和 Callable
TransmittableThreadLocal<String> context = new TransmittableThreadLocal<>();
// =====================================================
// 在父线程中设置
context.set("value-set-in-parent");
Runnable task = new RunnableTask();
// 额外的处理,生成修饰了的对象ttl
Runnable Runnable ttlRunnable = TtlRunnable.get(task);
executorService.submit(ttlRunnable);
// =====================================================
// Task中可以读取,值是"value-set-in-parent"
String value = context.get();2 修饰线程池
ExecutorService executorService = ...
// 额外的处理,生成修饰了的对象
executorService executorService = TtlExecutors.getTtlExecutorService(executorService);
TransmittableThreadLocal<String> context = new TransmittableThreadLocal<>();
// =====================================================
// 在父线程中设置
context.set("value-set-in-parent");
Runnable task = new RunnableTask();
Callable call = new CallableTask();
executorService.submit(task);
executorService.submit(call);
// =====================================================
// Task或是Call中可以读取,值是"value-set-in-parent"
String value = context.get();3 ### 使用 Java Agent 来修饰 JDK 线程池实现类
// ## 1. 框架上层逻辑,后续流程框架调用业务 ##
TransmittableThreadLocal<String> context = new TransmittableThreadLocal<>();
context.set("value-set-in-parent");
// ## 2. 应用逻辑,后续流程业务调用框架下层逻辑 ##
ExecutorService executorService = Executors.newFixedThreadPool(3);
Runnable task = new RunnableTask();
Callable call = new CallableTask();
executorService.submit(task);
executorService.submit(call);
// ## 3. 框架下层逻辑 ##
// Task或是Call中可以读取,值是"value-set-in-parent"
String value = context.get();使用java agent方式的好处是对应用代码无侵入,坏处的话我觉得最大的问题是如果启动jvm忘了加参数,那可能就会出事故。
简单看下源码逻辑

针对问题B,其实在应用开发中一般不会考虑这个问题,因为对时间效率的敏感性没有那么高。但是在一些底层的中间件开发中,对于性能优化可能就比较重视了。比如netty是选择自己实现了FastThreadLocal代替jdk的ThreadLocal,同时提供了配套的FastThreadLocalThread,在FastThreadLocalThread和FastThreadLocal搭配使用的情况下,可以始终保证O(1)查找时间复杂度,它的解决方案的原理就是空间换时间,为了避免哈希表出现哈希冲突后降低查询效率,会生成一个足够长的数组,每个FastThreadLocal构建时都会分配一个唯一的数组索引,相当于一人一个坑,查询时拿着自己的index直接从数组中取就可以了。
简单贴一下源码
